ファイルからデータを取得する
Kotlin Notebook は、Kotlin DataFrame ライブラリと組み合わせることで、非構造化データと構造化データの両方を扱うことができます。この組み合わせにより、TXT ファイルに含まれるデータなどの非構造化データを、構造化されたデータセットに変換する柔軟性が得られます。
データの変換には、.add()、.split()、.convert()、.parse() などのメソッドを使用できます。さらに、このツールセットを使用すると、CSV、JSON、XLS、Parquet、Apache Arrow など、さまざまな構造化ファイル形式からデータを取得し、操作することができます。 サポートされているすべての形式については、DataFrame のドキュメントを参照してください。
このガイドでは、複数の例を通して、データの取得、精製、および処理の方法を学ぶことができます。
始める前に
Kotlin Notebook は、IntelliJ IDEA にデフォルトでバンドルされ、有効になっている Kotlin Notebook プラグインに依存しています。
Kotlin Notebook の機能が利用できない場合は、プラグインが有効になっていることを確認してください。詳細については、「環境の設定」を参照してください。
このチュートリアルに従うには:
新しい Kotlin Notebook を作成します。
Kotlin DataFrame をインポートします:
kotlin%use dataframe
DataFrame ライブラリとその API をノートブックで確実に利用できるようにするために、他のコードセルを実行する前に
%use dataframeの行を含むコードセルを実行してください。
データの取得
Kotlin Notebook でファイルからデータを取得するには、DataFrame.read() 関数を使用します。
val movies = DataFrame.read("movies.csv")DataFrame.read() 関数は、ファイルの拡張子と内容に基づいて入力形式を自動的に検出します。
また、DataFrame ライブラリが入力データを読み込む方法を制御するために、追加の引数を渡すこともできます。例えば、次のコードは CSV ファイルにカスタム区切り文字(;)を指定しています:
val movies = DataFrame.read("movies.csv", delimiter = ';')追加のファイル形式やさまざまな読み込み関数の包括的な概要については、Kotlin DataFrame ライブラリのドキュメントを参照してください。
データの表示
データをノートブックに読み込んだら、それを表示できます。最も簡単な方法は、データを変数に保存してから、その変数を返すことです:
val jsonDf = DataFrame.read("jsonFile.json")
jsonDfこのコードは、ファイルからのデータをインタラクティブなテーブルとして表示します:
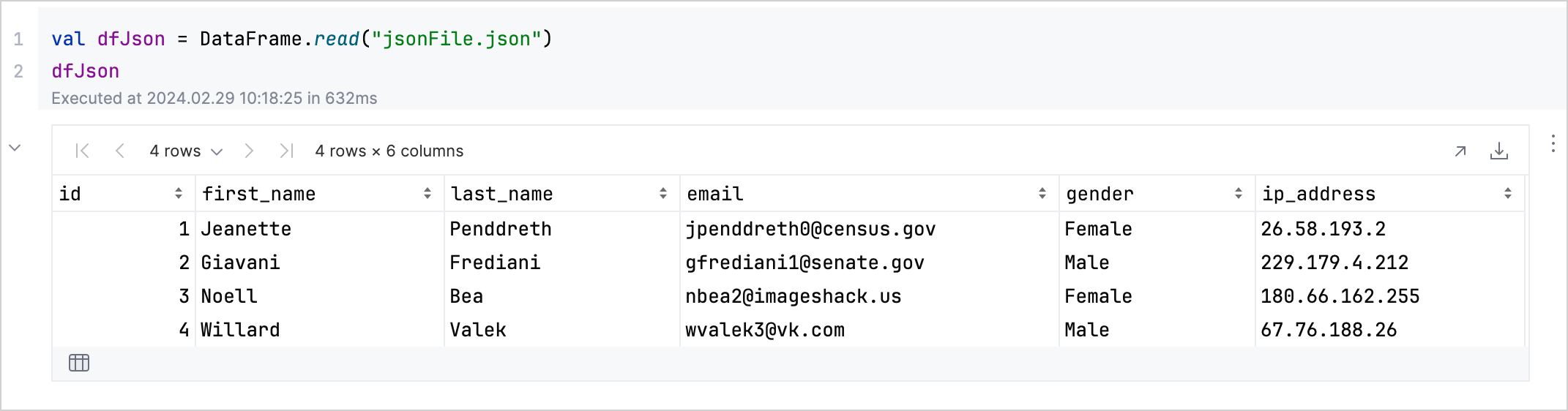
このビューを使用して、値の検査、列名の確認、データセットの状態の把握を簡単に行うことができます。
データ構造の検査
データの構造やスキーマを把握するには、DataFrame 変数に対して .schema() 関数を使用します。
例えば、jsonDf.schema() を実行して、JSON データセット内の各列の型をリスト表示します:
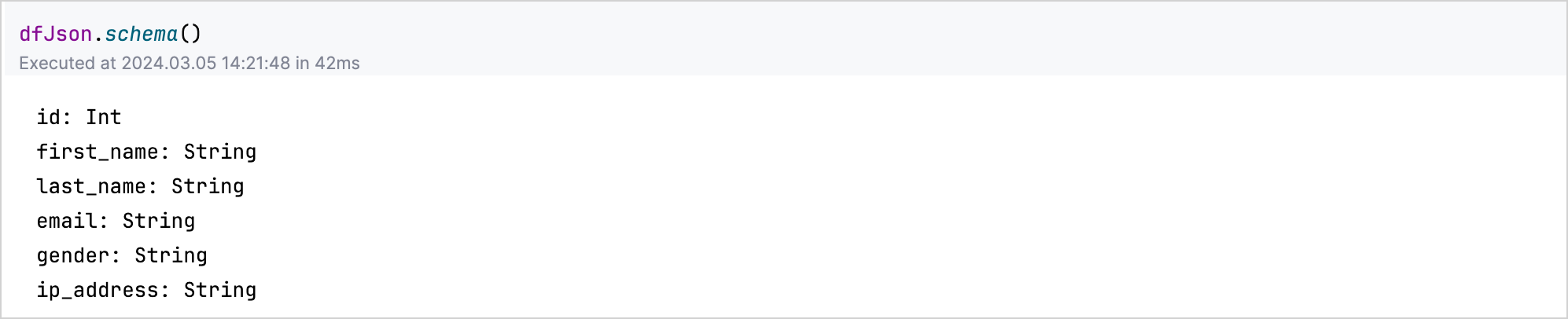
Kotlin Notebook では、オートコンプリート機能も使用できます。これにより、DataFrame のプロパティに素早くアクセスし、操作することができます。データを読み込んだ後、DataFrame 変数の後にドット(.)を入力するだけで、利用可能な列とその型の一覧が表示されます。
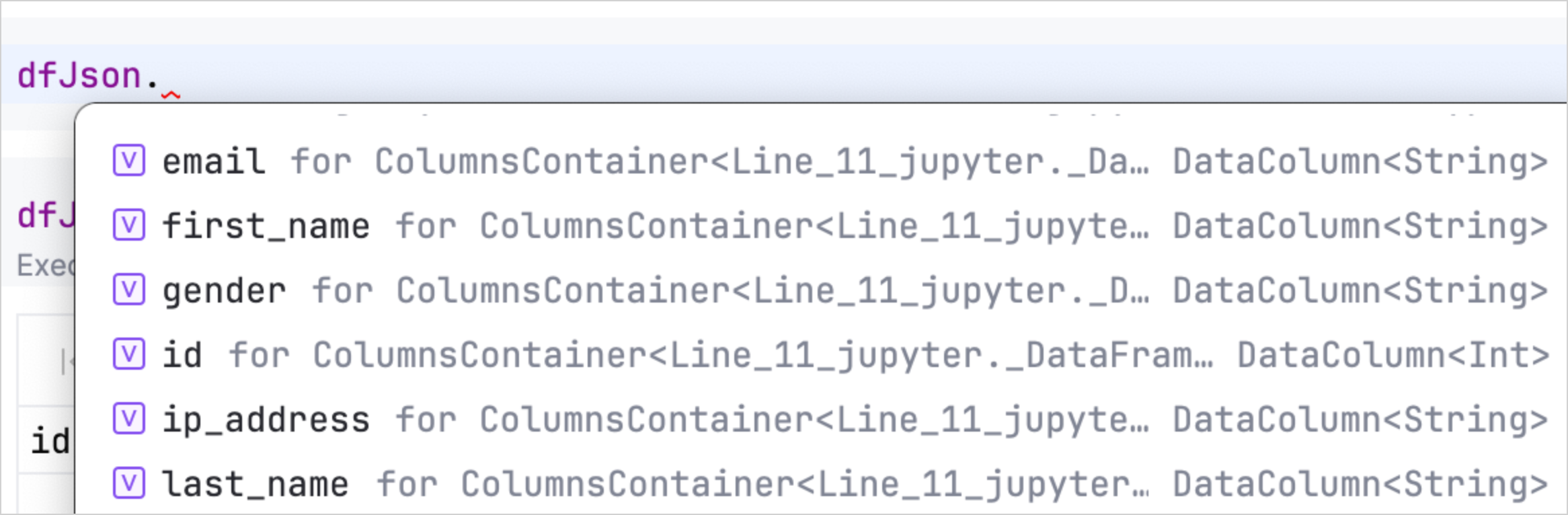
データの精製
Kotlin DataFrame は、データセットを精製するためのさまざまな操作を提供しています。例えば、グルーピング、フィルタリング、更新、新しい列の追加などがあります。これらの関数はデータ分析に不可欠であり、データを効果的に整理、クリーンアップ、変換することができます。
例として、movies.csv データセットを見てみましょう。このデータセットでは、映画のタイトルと同じセルに公開年が保存されています。目標は、分析しやすくするためにこのデータセットを精製することです:
データの読み込み
.read()関数を使用して、ファイルをDataFrameに読み込みます:kotlinval movies = DataFrame.read("movies.csv")列の追加
title列から公開年を抽出するために、新しいyear列を追加します:kotlinval moviesWithYear = movies .add("year") { "\\d{4}".toRegex() .findAll(title) .lastOrNull() ?.value ?.toInt() ?: -1 } moviesWithYear値の更新
映画のタイトルから公開年を削除するために、
title列を更新します:kotlinval moviesTitle = moviesWithYear .update("title") { "\\s*\\(\\d{4}\\)\\s*$".toRegex().replace(title, "") } moviesTitleこのコードにより、映画のタイトルが 1 つの列に保持され、公開年が別の列に移動します。
行のフィルタリング
特定のデータに焦点を当てるには、
.filter()関数を使用します。例えば、1986 年より後に公開された映画のみを保持するには、次を実行します:kotlinval newMovies = moviesTitle.filter { year >= 1996 } newMovies列の削除
不要な列を削除するには、
.remove()関数を使用します:kotlinval refinedMovies = newMovies.remove { movieID } refinedMovies
比較のために、精製前のデータセットを以下に示します:
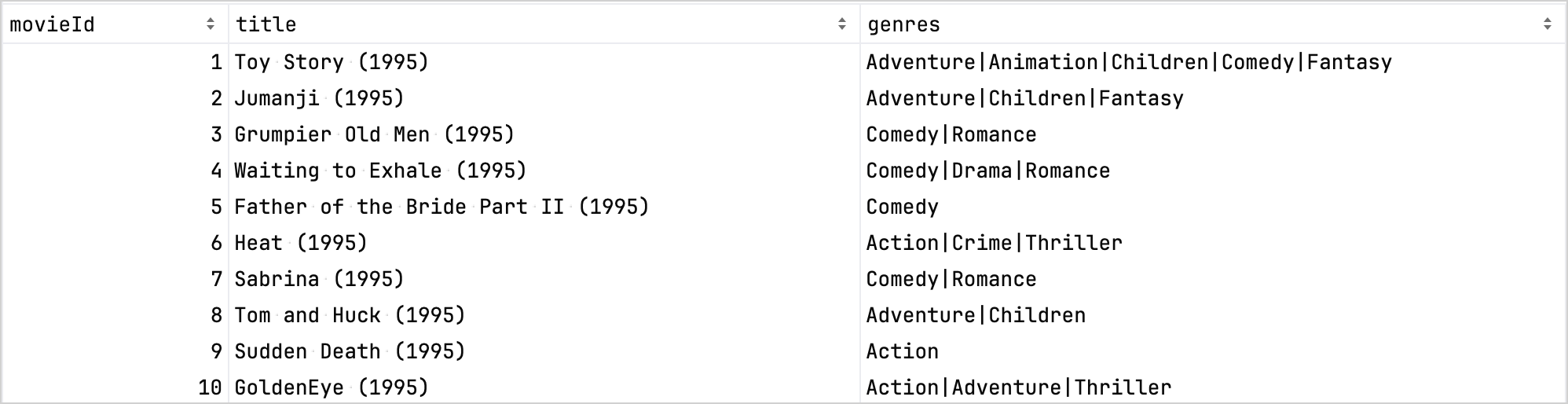
精製後のデータセット:

追加のユースケースや詳細な例については、Kotlin DataFrame の例を参照してください。
データの書き出し
Kotlin Notebook でデータを精製した後、処理済みのデータを簡単にエクスポートできます。
この目的のために、さまざまな .write() 関数を利用できます。CSV、JSON、XLS、XLSX、Apache Arrow、さらには HTML テーブルなど、複数の形式での保存をサポートしています。 サポートされているすべての形式については、DataFrame のドキュメントを参照してください。 これは、知見を共有したり、レポートを作成したり、さらなる分析のためにデータを利用可能にしたりするのに特に役立ちます。
例えば、結果を次のように保存してみましょう:
.writeJson()関数を使用した JSON ファイル:kotlinrefinedMovies.writeJson("movies.json").writeCsv()関数を使用した CSV ファイル:kotlinrefinedMovies.writeCsv("movies.csv").writeArrowIPC()および.writeArrowFeather()関数を使用した Apache Arrow ファイル:kotlinrefinedMovies.writeArrowIPC("movies.arrow") refinedMovies.writeArrowFeather("movies.feather")
また、.toStandaloneHTML() 関数を使用して、ブラウザでスタンドアロンの HTML テーブルを開くこともできます:
refinedMoviesDf
.toStandaloneHTML(DisplayConfiguration(rowsLimit = null))
.openInBrowser()次のステップ
- Kandy ライブラリを使用したデータの可視化を探索する
- Kandy を使用した Kotlin Notebook でのデータの可視化でデータの可視化に関する追加情報を見つける
- Kotlin でのデータサイエンスと分析に利用可能なツールとリソースの広範な概要については、データ分析用の Kotlin および Java ライブラリを参照してください。